1. ML: Basic Fundamentals
#Dataset Representation
Tabular datasets consists of rows and columns :
Rows : Also called data points, samples, observations, instances, patterns.
- Each row reprsents a single observation.
Columns : Also called variables, characteristics, features, attribute.
- Each columns represents a measurable property or attribute of that observation.
| H | W | ||
|---|---|---|---|
| 130 | 55 | ||
| 140 | 65 | ||
| 160 | 75 |
To perform statistical analysis, the datasets is viewed as samples drawn from a probability distribution.
Each feature (column) is treated as Random Variable ().
- A RV is a function that maps outcomes of a random phenomenon to numerical values.
- Thus, is a rv describing the distribution of heights feature in the population.
A single row containing features is a random vector.
- If the dataset has features , , , , then a single observation is a vector .
Thus, the entire dataset is a collection of observed random vectors :
Thus, the full table can be visualized like :
#Measures of Central Tendencies
#Moment 1
#1. Mean
- For a dataset :
Where :
And thus the resulting mean vector is a collection of these individual feature means :
#2. Median
First, sort the data in ascending order.
If odd no. of values :
If even no. of values :
Note
When outliers are present in the dataset, it is better to use median.
#Moment 2 (Measures of Dispersion)
#3. Variance
Measures how far are data points spread out from the mean.
- It heavily weight the outliers because it squares the difference.
#4. Standard Deviation
- Square root of variance.
- It measures the average distance of data points from the mean.
#5. Range
#Moment 3 / Skewness
Measures the asymmetry / symmetry of the distribution around the mean.
- Positive Skew : Tail extends to the right (right skewed).
- Negative Skew : Tail extends to the left (left skewed).
- Zero Skew : Perfectly symmetrical (like a standard Normal distribution).
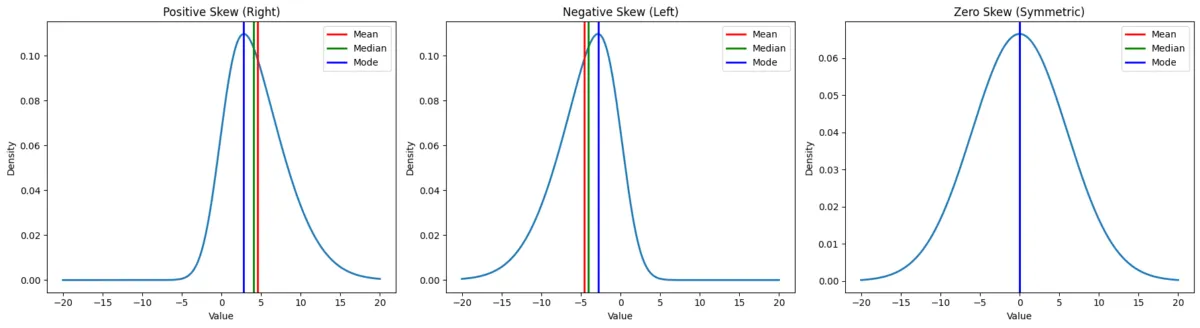
Skewness
#Moment 4 / Kurtosis
It defines the shape in terms of peak (sharpness) and tail (heaviness).
Bessel's Correction
In the denominator, use when a sample of the population is considered. Otherwise, when the whole population is used, use .
#Box Plot
It is a standard way of displaying the distribution of data based on 5-number summary.
- Minimum () : lowest data point excluding any outliers.
- First Quartile ( / 25th Percentile) : The value below which 25% of the data falls. The bottom of the box.
- Median ( / 50th Percentile) : The middle value of the dataset. The line inside the box.
- Third Quartile ( / 75th Percentile) : The value below which 75% of the data falls. The top of the box.
- Maximum () : The highest data point excluding any outliers.
Interquartile Range (IQR) : The height of the box (). It represents the middle 50% of the data.
Whiskers : Lines extending from the box indicating variability outside the upper and lower quartiles.
- Set to and
Outliers : Individual points plotted beyond the whiskers.
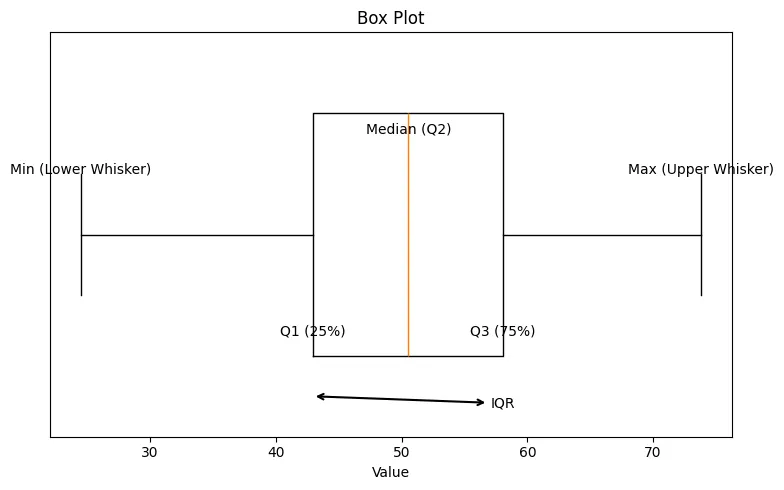
Box Plot
#Covariance and Correlation
When analysing 2 features or Random Variables ( and ), it is better to look at their joint variability.
#Covariance
It measures the direction of the linear relationship between variables.
- Positive Covariance : As increases, tends to increase.
- Negative Covariance : As increases, tends to decrease.
- Zero Covariance : No linear relationship between the 2 RVs.
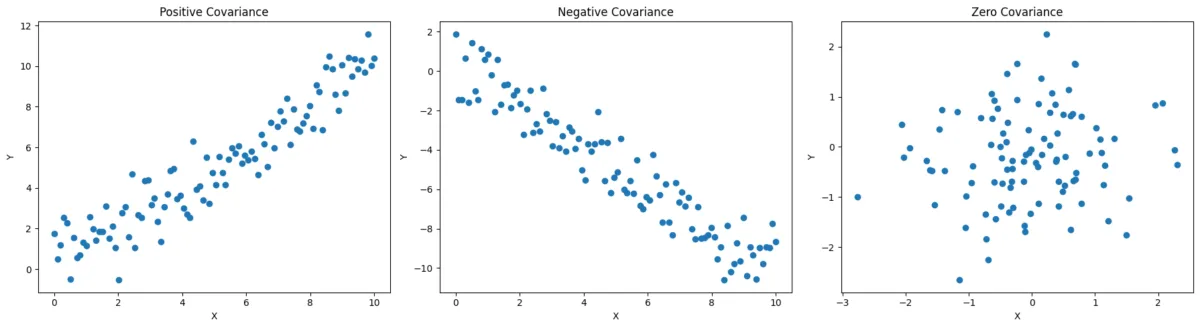
Covariance
#Correlation
It is the normalized version of covariance. It measures both the strength and direction of linear relationship.
- It is the Pearson Correlation Coefficient.
- It will always be between 1 and -1.
Mathematical Property
Covariance of a RV '' with itself will be
Thus, .
#Covariance Matrix
For a random vector with features, the relation between all features can be summarized using the Covariance Matrix .
- It is a matrix.
- Diagonal elements : Variance of individual terms.
- Off-Diagonal elements : Covariances between feature pairs.
- , this means that the matrix is symmetric.
Key Insights
If one feature is a perfect linear combination of other features, then there is redundancy in the information, and the covariance matrix is singular (i.e., its rank is less than the number of features).
#Correlation Matrix
While the Covariance Matrix tells the direction of the relationship and the spread, the Correlation Matrix provides a normalized score of the relationship strength, making it easier to compare features with different units (e.g., comparing "Height in cm" vs. "Weight in kg").
- : It is the Pearson Coefficient.
- It is between .
- It is also a symmetric matrix.
#Types of Machine Learnings
- Supervised Learning
- Model learns from labelled data. For every input, the correct output is already known. The goal is for the algorithm to learn the mapping function from the input to the output.
- Eg. : Linear Regression, Logistic Regression, SVM, Decision Tree, KNN, Neural Networks, etc.
- Use cases : Email spam filtering, Medical diagnosis, Credit Scoring, etc.
- Unsupervised Learning
- The model works with unlabelled data and finds hidden patterns.
- Eg. Clustering, Dimensionality Reduction (PCA)
- Use cases : Customer segmentation, Anomaly detection, Association discovery
- Semi-Supervised Learning
- The model is trained on a small amount of labeled data and a large amount of unlabeled data.
- eg. Self-training models, Transformers
- Image classification when labelling data is expensive.
- Reinforcement Learning
- An agent learns to make decisions by performing actions in an environment to achieve a goal. It receives rewards for good actions and penalties for bad ones.
- Examples : Policy Gradient Methods
- Use cases : Robotics, Self-driving cars, Game plating (chess, go)
#Supervised Learning
- Start with a labelled dataset where input (features) and outputs (labels) are known.
- Split the dataset into
train-test.
- Training Set : Used to build and tune models.
- It is split into 2 parts :
- Train split
- Validation split
- It is split into 2 parts :
- Test Set : Held out and never used during training or model selection. It is only used at the very end to estimate real-world performance.
- Using the training set, multiple candidate models are fitted based on different hyperparameters or algos.
- Validation set is used to evaluate these models during development.
- Based on the validation performance the best model is selected (highest validation accuracy, lowest loss).
- The selected model becomes the final trained model.
- It is evaluated on the test set, producing an unbiased estimate of the performance.
With this, the basics are over.