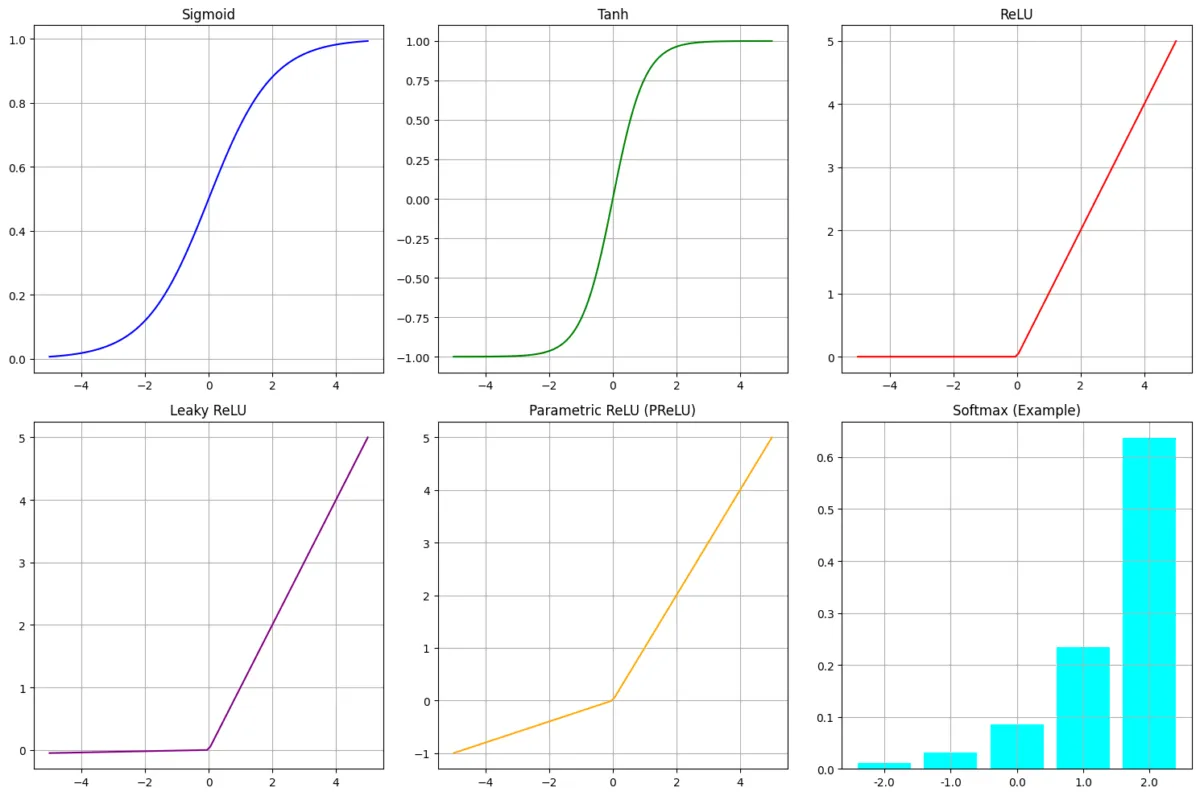
3. Neural Nets: Activation Functions
#Activation Functions
- It is used to introduce non-linearity into the neural network.
- This allows to model complex relatioships in data.
#Why activation functions are needed ?
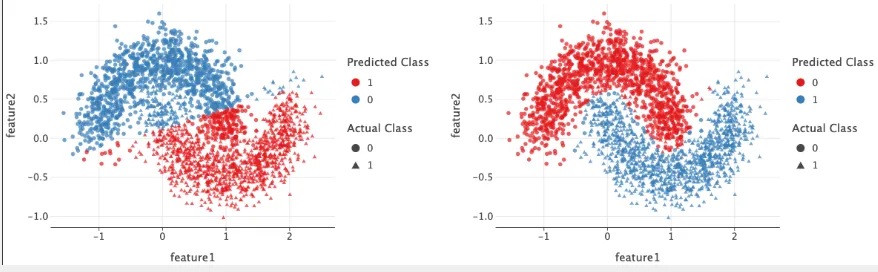
The data on left can be modelled by using a linear function.
- The data is linearly separable.
- linear activation / no activation is sufficient.
But the data on right can't be modelled using linear function
- Linear model will fail here because it can only create a straight-line decision boundary.
- Therefore, a non-linearity is required to model the data.
Without activation functions, deep networks behave like a simple linear model, limiting their capability.
#Types of Activation functions
import torch
import torch.nn as nn
#1. Linear Activation Funtion
- Output is proportional to input
- Doesn't introduce non-linearity.
- Rarely used.
PyTorch Implementation :
linear_activation = nn.Identity()
x = torch.tensor([1.0, 2.0, 3.0])
output = linear_activation(x)
#2. Sigmoid Activation
Output in range (0,1).
Used in binary classification problems.
Can be interpreted as probabilities (used in logistic regression).
Drawback
- Vanishing gradient problem
- When inputs are large/small, gradients become very small.
- Vanishing gradient problem
PyTorch Implementation :
sigmoid = nn.Sigmoid()
x = torch.tensor([-1.0, 0.0, 1.0])
output = sigmoid(x)
#3. Hyperbolic Tangent (Tanh)
Output in range in (-1,1)
Centered around 0, helps in faster convergence
Usefull for hidden layers in deep networks.
Drawback
- Vanishing Gradient Problem (better than sigmoid)
- Computationally expensive
PyTorch Implementation :
tanh = nn.Tanh()
output = tanh(x)
#4. Rectifed Linear Unit (ReLU)
Most widely used activation function.
Output in range .
Solves vanishing gradient problem (because no exponentials).
Efficient computation.
Sparse activation (many neuron output 0).
Drawback
- Dying ReLU Problem (Neurons that output zero remain inactive).
- Not centered around zero.
PyTorch Implementation :
relu = nn.ReLU(x)
output = relu(x)
#5. Leaky ReLU
Output in range .
Mmodified ReLU, allows a small gradient for negative inputs
Default
Prevents Dying ReLU Problem
Drawback
- Requires tuning of slope
PyTorch Implementation :
leakyrelu = nn.LeakyReLU(negative_slop=0.01)
ouyput = leakyrelu(x)
#6. Parametric ReLU (PReLU)
Output in range .
Unlike Leaky ReLU, is learned during training.
Same equation as Leaky ReLU
Adaptive slope improves performance
Avoids dying ReLU issue.
Drawback
- Extra parameter α increases computation.
PyTorch Implementation :
prelu = nn.PReLU()
output = prelu(x)
#7. Exponential Linear Unit (ELU)
Output in range .
Smooths out the output for negative values
Avoids dying ReLU.
Helps with vanishing gradients
Drawback
- More computationally expensive.
PyTorch Implementation :
elu = nn.ELU(alpha=1.0)
output = elu(x)
#8. Softmax
output in range .
Used in the final layer of classification networks. (Multi- CLass)
Outputs probabilities.
Converts logits(unnormalized scores) into probabilities summing to 1.
Drawback
- Can be overconfident in predictions (sensitive to large values)
PyTorch Implementation :
softmax = nn.Softmax(dim=1) # axis 1 across row
output = softmax(torch.tensor([[1.0, 2.0, 3.0]]))
#Summary
- Activation functions introduce non-linearity to neural networks.
- ReLU is widely used in deep learning due to its efficiency.
- Tanh is preferred over Sigmoid due to its zero-centered outputs.
- Softmax is essential for multi-class classification tasks.
Choosing the right activation function is crucial for model performance and convergence stability.
Plot of some of the activation functions