5. Computer Vision: Semantic Segmentation
Image Segmentation
- A segmentation algorithm takes an image as input and outputs a collection of regions (or segments) which can be represented as
- A collection of contours.
- A mask (either grayscale or color ) where each segment is assigned a unique grayscale value or color to identify it.
Superpixels : perceptually meaningful groups of pixels formed by clustering neighboring pixels that have similar low-level properties such as color, texture, intensity, or spatial proximity.
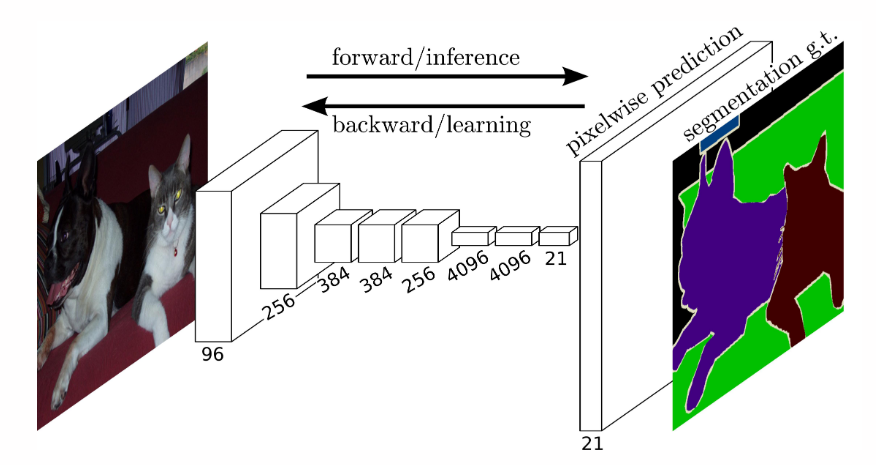
Semantic Segmentation
- Image analysis task in which each pixel is classsified into a class.
Performing Semantic Segmentation using PyTorch
- Input : 3 channeled image which is normalized with the Imagenet mean and standard deviation.
mean = [0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225]- [Ni x Ci x Hi x Wi]
Ni= batch size
- Output :
[No x Co x Ho x Wo]No= batch size (same asNi)Co= number of classes that the dataset have- the models from
torchvision.modelsgenerally return anOrderedDictwhen used inmodel.eval()mode (evaluation/inference mode). output = model(input_tensor)out_tensor = output['out'] # Shape: [N, C, H_out, W_out]- thus
outkey of theOrderedDictholds the output tensor
- thus
FCN with Resnet-101 backbone
-
FCN = Fully Convolutional Networks
-
fcn = models.segmentation.fcn_resnet101(
weights=models.segmentation.FCN_ResNet101_Weights.DEFAULT
).eval()
Preprocessing the image
import torchvision.transforms as T
trf = T.Compose([T.Resize(256),
T.CenterCrop(224),
T.ToTensor(),
T.Normalize(mean = [0.485, 0.456, 0.406],
std = [0.229, 0.224, 0.225])])
Passing the image to model
img = Image.open(path).convert(RGB)
inp = trf(img).unsqueeze(0)
out = fcn(inp)['out']
print (out.shape) # torch.Size([1, 21, 224, 224])
- Unsqueeze the image so that it becomes
[1 x C x H x W]from[C x H x W]- Because a batch dimension must be needed when passed to the model.
-
output of the model is a
OrderedDictso, take theoutkey from that to get the output of the model. - model was trained on 21 classes and thus output has 21 channels.
Converting the tensor to a 2D image
import numpy as np
om = torch.argmax(out.squeeze(), dim =0).detach().cpu().numpy()
print(om.shape)
print(np.unique(om))
om = torch.argmax(out.squeeze(), dim =0).detach().cpu().numpy().squeeze(): removes dimension of size 1- thus,
[1, C, H, W]becomes[C, H, W]
- thus,
torch.argmax(input, dim=0)- returns the indices of the maximum values along a specified dimension (0).
- here the input is
[C, H, W], where each if theCchannels contains the score for that class at each pixel. - thus, At every pixel
(h, w), find the class indexcwhere the value is highest. - This gives a 2D tensor
-
For each pixel (i.e., for each (h, w)), look across classes (dim=0), and pick the class with the highest score.
.detach()- Detaches the tensor from the computation graph (so no gradients will be tracked).
.cpu()- Moves the tensor to the CPU.
.numpy()- converts the tensor to a numpy array.
-
om : A 2D NumPy array of shape (H, W) where each value is a class index from 0 to 20.
Converting the segmentation map into a colour image
def decode_segmap(image, nc = 21):
label_colors = np.array([(0, 0, 0), # 0=background
# 1=aeroplane, 2=bicycle, 3=bird, 4=boat, 5=bottle
(128, 0, 0), (0, 128, 0), (128, 128, 0), (0, 0, 128), (128, 0, 128),
# 6=bus, 7=car, 8=cat, 9=chair, 10=cow
(0, 128, 128), (128, 128, 128), (64, 0, 0), (192, 0, 0), (64, 128, 0),
# 11=dining table, 12=dog, 13=horse, 14=motorbike, 15=person
(192, 128, 0), (64, 0, 128), (192, 0, 128), (64, 128, 128), (192, 128, 128),
# 16=potted plant, 17=sheep, 18=sofa, 19=train, 20=tv/monitor
(0, 64, 0), (128, 64, 0), (0, 192, 0), (128, 192, 0), (0, 64, 128)])
r = np.zeros_like(image).astype(np.uint8)
g = np.zeros_like(image).astype(np.uint8)
b = np.zeros_like(image).astype(np.uint8)
for l in range(0, nc):
idx = image == l
r[idx] = label_colors[l, 0]
g[idx] = label_colors[l, 1]
b[idx] = label_colors[l, 2]
rgb = np.stack([r, g, b], axis=2)
return rgb
nc=21: default number of classes = 21label_colors: lookup table of RGB colors where each index i corresponds to the RGB color of class i.r = np.zeros_like(image).astype(np.uint8)- create empty color channels for each r, g, b.
- they have the same shape as the input image but hols color values (0-255), thus
np.uint8
idx = image == 1- looping over all the class index from 0 to
nc-1 idxis a boolean mask.- it creates a boolean array of same shape as image.
Truewhen a pixel of the image has the same value as the labell.
- looping over all the class index from 0 to
r[idx] = label_colors[l, 0]- In array
r, wherever idx isTrueset the value to the [0] of thelchannel. - same for other colurs.
- In array
rgb = np.stack([r, g, b], axis = 2)- all the 3 separate 2D arrays are combined into a 3D array which is a single RGB image os shape
height, width, 3. axis = 2: these arrays are stacked along a new 3rd axis (channel axis).- axis 0 = height, axis 1 = width, axis 2 = color channels
- all the 3 separate 2D arrays are combined into a 3D array which is a single RGB image os shape
Final segmented image
rgb = decode_segmap(om)
plt.imshow(rgb)
plt.show()
DeepLabv3 model
dlab = models.segmentation.deeplabv3_resnet101(
weights='COCO_WITH_VOC_LABELS_V1').eval()
- It is also another model which is used for segmenatation tasks.
- It performs better than FCN
Metrics for evaluation of segmentation models
- mAP : mean Average Precision, evaluate the precision-recall curve.
- Recall : measure how well the model captures all relevant pixels (true positives).
- Dice coefficient : measures the overlap between predicted and ground truth masks.
-
\[Dice = \frac{2 . |A \cup B|}{|A| + |B|}\]
A: predicted maskB: ground truth mask|A ∩ B|: number of pixels where both masks overlap (true positives)
-
\[Dice = \frac{2 . |A \cup B|}{|A| + |B|}\]
Datasets for Semantic segmentation
- ADE20K
- PASCAL VOC (2007-2012)
- COCO Stuff
- Cityscapes
Colab Notebook with the complete implementation can be accessed here