3. NLP: Pytorch for NLP
Loading Custom Data
- Data can be available in many formats like
csv,jsonorplain text. - Let’s look at how to handle each type of data.
CSV data
- Given data is like :
text,label
"I love deep learning",1
"NLP is fun",0
"Transformers are powerful",1
"PyTorch makes it easy",0
It can be processed using pandas library.
import pandas as pd
df = pd.read_csv('data.csv')
texts = df['text'].astype(str).tolist() # list of text strings
labels = df['label'].tolist() # list of labels (e.g. integers or categories)
This will give 2 lists texts and labels.
JSON
- Given data is like :
[
{"text": "I love deep learning", "label": 1},
{"text": "NLP is fun", "label": 0},
{"text": "Transformers are powerful", "label": 1},
{"text": "PyTorch makes it easy", "label": 0}
]
It can be processed using the json module
import json
with open('data.json') as f:
records = json.load(f) # records = list of dict.
texts = [rec['text'] for rec in records]
labels = [rec['label'] for rec in records]
Alternatively, df = pd.read_json('data.json) can also be used.
Plain Text
- Assuming there are 2 different files for text and labels
texts = []
with open('data.txt', 'r', encoding='utf-8') as f:
for line in f:
line = line.strip()
if line:
texts.append(line)
- Same can be done for labels file too.
Preprocessing text with NLTK
- Using
nltk(Natural Language Toolkit) library for preprocessing textual data. - It provides various methods to clean the raw text before converting to tenors.
Tasks to be performed :
| Task | Purpose | Implementation | |
|---|---|---|---|
| 1 | Lower casing | for uniformity | lower() |
| 2 | Tokenization | Split text into tokens(words) | sent_tokenize() & word_tokenize() |
| 3 | Punctuation Removal | Doesn’t add any meaningful information | regex [^\w\s] |
| 4 | Removing stop words | Remove common, less informative words (eg. the, is, a) | nltk.corpus.stopwords.words() |
| 5 | Stemming | Reduce word to their root form (may not be acurate words) | nltk.stem.PorterStemmer() |
| 6 | Lemmatization | Reduce words to their base/dictionary form | nltk.stem.WordNetLemmatizer() |
Complete function
import nltk
nltk.download('punkt') # for tokenization
nltk.download('stopwords')
nltk.download('wordnet') # for lemmatization
from nltk.tokenize import word_tokenize
import re
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
def preprocess_text(text):
tokens = word_tokenize(text.lower()) # tokenzie as well as lower case the text
tokens = [re.sub(r'[^\w\s]', '', token) for token in tokens] # remove all punctuations or Remove non-word/non-space chars
tokens = [token for token in tokens if token] # remove empty tokens that may arrise from punctuation removal
stop_words = set(stopwords.words('english'))
tokens = [token for token in tokens if token not in stop_words] # remove stopwords
lemmatizer = WordNetLemmatizer()
tokens = [lemmatizer.lemmatize(token) for token in tokens]
return tokens
Example of the above code :
text = "The striped bats are hanging on their feet for best."
print(preprocess_text(text))
# Output: ['striped', 'bat', 'hanging', 'feet', 'best']
Creating a Vocabulary
- The tokenized text needs to be mapped to a unique numerical index.
- Vocabulary : set of unique tokens present in the training corpus mapped to indices.
- This allows to us represent text sequences as sequences of numbers.
Implementation
import collections
from collections import Counter
class Vocabulary:
def __init__(self, freq_threshold=1):
# first 2 entries in the mappings are special tokens
'''<PAD> = 0, This implies if padding is used it will reprsented by 0'''
'''<UNK> = 1, This implies if a unknow word comes it will reprsented by 1'''
self.itos = {0:"<PAD>", 1:"<UNK>"} # index to string mapping = itos
self.stoi = {"<PAD>":0, "<UNK>":1} # string to index mapping = stoi
# to consider only those words which appear more than a certain number of times
self.freq_threshold = freq_threshold
self.word_counts = Counter() # to count the frequenct if each token
def __len__(self):
return len(self.itos)
def add_sentence(self, sentence_tokens):
# all the tokens from the sentence to counter
self.word_counts.update(sentence_tokens)
def build_vocabulary(self, sentence_list):
# sentence_list = list of tokenized sentences
for sentence_tokens in sentence_list:
self.add_sentence(sentence_tokens)
idx = len(self.itos) # start indexing after special tokens
for word, count in self.word_counts.items():
if count >= self.freq_threshold :
if word not in self.stoi: # avoid re-adding
self.stoi[word] = idx
self.itos[idx] = word
idx += 1
def numericalize(self, text_tokens):
return [self.stoi.get(token, self.stoi["<UNK>"]) for token in text_tokens]
# Converts the list of tokens to a list of corresponding integer indices
Example execution :
tokenized_corpus = [["hello", "world"], ["hello", "pytorch", "nlp"]]
vocab = Vocabulary(freq_threshold=1)
- This will initialize
stoi&itosmapping :
stoi = {"<PAD>": 0, "<UNK>": 1}
itos = {0: "<PAD>", 1: "<UNK>"}
- Then :
vocab.build_vocabulary(tokenized_corpus)
- First, all tokens will be counted by
Counter.
word_counts = Counter({
"hello": 2,
"world": 1,
"pytorch": 1,
"nlp": 1
})
- Then, based on the count of each token
stoianditosmappings will be updated :
stoi = {
"<PAD>": 0,
"<UNK>": 1,
"hello": 2,
"world": 3,
"pytorch": 4,
"nlp": 5
}
itos = {
0: "<PAD>",
1: "<UNK>",
2: "hello",
3: "world",
4: "pytorch",
5: "nlp"
}
- Now, calling the
numericalizefunction :
vocab.numericalize(["hello", "new", "world"]) # output = [2, 1, 3]
<PAD>:
- Used for padding.
- Neural networks require inputs to be fixed size.
- Because text sequences have variable lengths, they are padded to a uniform length (max length).
<UNK>:
- Out-of-Vocabulary (OOV) words are those which are encountered in val/test set but not present in train set.
- These words are mapped to
token
Using build_vocab_from_iterator
- Generate the tokens :
# Step 1: Read and preprocess
preprocessed_texts = []
with open('data.txt', 'r', encoding='utf-8') as f:
for line in f:
line = line.strip()
if line:
tokens = preprocess_text(line)
preprocessed_texts.append(tokens)
- Buid vocabulary
from torchtext.vocab import build_vocab_from_iterator
vocab = build_vocab_from_iterator(preprocessed_texts, specials=['<PAD>', '<UNK>'])
vocab.set_default_index(vocab['<UNK>'])
Building Custom Dataset using Dataset Class
- Custom dataset are created by subclassing abstract class
torch.utils.data.Dataset. - It requires implementing 3 functions :
__init__: Initializes the dataset__len__: Returns the size of the dataset__getitem__: Retrieves a sample from the dataset.
from torch.utils.data import Dataset
class TextDataset(Dataset):
def __init__(self, texts, labels, vocab):
"""
texts: list of token lists
labels: list of labels
vocab: Vocabulary instance (with stoi dictionary)
"""
self.texts = texts
self.labels = labels
self.vocab = vocab.stoi
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
tokens = self.texts[idx]
indices = [self.vocab.get(token, self.vocab["<UNK>"]) for token in tokens] # looks up the index for each token
# if not found then defaults to <UNK>
label = self.labels[idx]
# returns 2 pytorch tensors
return torch.tensor(indices, dtype=torch.long), torch.tensor(label, dtype=torch.long)
Padding and Batching Sequence
- Neural networks require data in batches of equal shape.
- Because token sequences may vary in length, shorter sequences are handled by padding so that each tensor is of shape
[batch_size, max_seq_length]. - This is done using
collate_fnandtorch.nn.utils.rnn.pad_sequenceto pad dynamically. - Collate means to collect and combine.
from torch.nn.utils.rnn import pad_sequence
def collate_fn(batch):
texts, labels = zip(*batch)
padded_texts = pad_sequence(texts, batch_first=True, padding_value=vocab.stoi["<PAD>"])
labels = torch.stack(labels)
return padded_texts, labels
Explanation :
batch: list of samples.- Each sample in this list is entity returned by
__getiten__()function. - It will be a tuple.
- Each sample in this list is entity returned by
zip(*batch):*batchwill separate the batch tuple intp o 2 separate tuples.batch= [(text1, label1), (text2, label2), (text3, label3)]*batch= ((text1, text2, text3), (label1, label2, label3))
zip()groups the elements at the same position from these tuples.
pad_sequence(...):- It takes a list or tuple of tensors (texts) and pads them with a specified value
(padding_value)so that they all have the same length (the length of the longest tensor in the batch).
- It takes a list or tuple of tensors (texts) and pads them with a specified value
padding_value=vocab.stoi["<PAD>"]:- It indicates that the integer index associated with
<PAD>from stoi is the padding value.
- It indicates that the integer index associated with
torch.stack(labels):- concatenates a sequence of tensors along a new dimension.
- it takes the tuple of individual label tensors (labels) and stacks them into a single tensor.
Thus this function takes a list of (text_tensor, label_tensor) pairs, separates the text tensors and label tensors, pads the text tensors to the maximum length within that batch using a designated padding value, stacks the label tensors, and returns the padded batch of texts and the batch of labels.
Loading the data
- Using
torch.utils.data.DataLoaderwhich will take a Dataset object and provides an iterable over the dataset.
# Suppose all_tokenized_texts = [preprocess_text(t) for t in raw_texts]
# and all_labels = [0, 1, 0, 1, ...] (binary or multi-class)
vocab = Vocabulary(freq_threshold=1)
vocab.build_vocabulary(all_tokenized_texts)
dataset = TextDataset(all_tokenized_texts, all_labels, vocab)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True, collate_fn=collate_batch, num_workers=2)
num_workers: How many subprocesses to use for data loading.- Using more workers can speed up data loading.
Working of nn.Embedding
Once texts are converted to indices and padded, we feed them into an
nn.Embedding layer.
- It is a PyTorch layer that acts as a simple learnable lookup table.
- It stores dense vector representations (embeddings) for a fixed dictionary of items (words or tokens).
- When an integer index (representing a word) in passed as input, the layer returns the corresponding embedding vector.
-
Each item is represented by vector of fixed length where most or all values are non-zero.
- Each token index passes through this embedding layer to produce a dense vector.
-
The words in a sentence are first converted to indices via the vocabulary, then the embedding layer outputs a vector for each index.
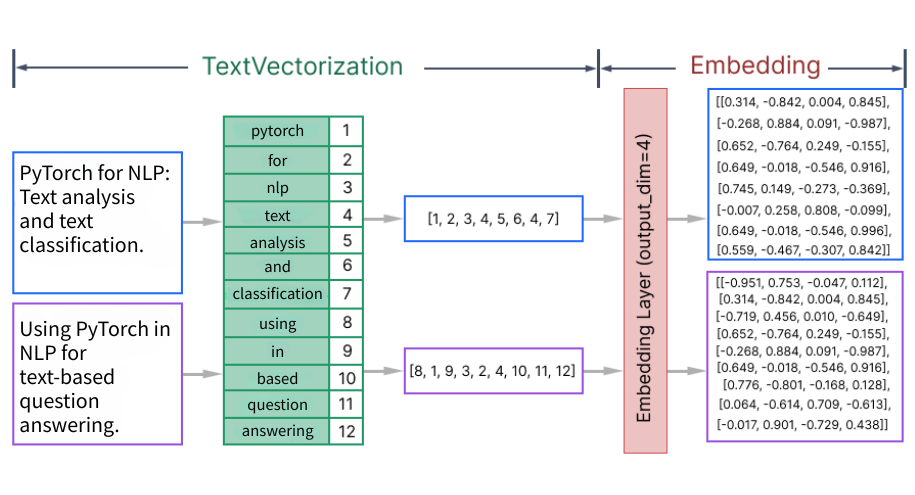
embedding = nn.Embedding(num_embeddings = len(vocab), embedding_dim=100, padding_idx=vocab['<PAD>'])
padding_idx: The embedding vector at this index will not be updated during training.
Why not use one-hot encoding?
- Sparse one-hot encoding will have vocabulary size dimensions,
nn.Embeddingare dense and much lower dimensions. - Embeddings learn to capture semantic relationships between words during training.
Using pretrained embeddings
- Instead of learning embeddings from scratch,
nn.Embeddingcan be initialized with pre-trained vectors such as GloVe. - The embedding can be downloaded from here.
- It will contain different text files whcih will have vectors of different dimensions (indicated in their name).
import torch
# Load GloVe embeddings from file into a dict
glove_path = 'glove.6B.100d.txt'
glove_vectors = {}
with open(glove_path, 'r', encoding='utf-8') as f:
for line in f:
parts = line.strip().split()
word, vec = parts[0], parts[1:]
glove_vectors[word] = torch.tensor(list(map(float, vec)))
'''
Each line is like :
apple 0.123 0.532 ... (100 numbers in total)
'''
# Create embedding weight matrix for the vocab
embedding_dim = 100
weights_matrix = torch.zeros(vocab_size, embedding_dim)
for word, idx in vocab.items():
vector = glove_vectors.get(word)
if vector is not None:
weights_matrix[idx] = vector
# Create Embedding layer using from_pretrained (freezing weights)
embedding_glove = nn.Embedding.from_pretrained(weights_matrix, freeze=True, padding_idx=vocab['<PAD>'])
Implement the LSTM model
- The embedding layer can now be used in a model.
- Below is code for LSTM model for text classification tasks.
class TextLSTM(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, n_layers=1, bidirectional=False, dropout=0.5):
super().__init__()
# Embedding layer
self.embedding = nn.Embedding(vocab_size, embedding_dim)
# LSTM layer
self.lstm = nn.LSTM(
embedding_dim,
hidden_dim,
num_layers=n_layers,
bidirectional=bidirectional,
batch_first=True,
dropout=0 if n_layers < 2 else dropout
)
# Output layer
self.fc = nn.Linear(
hidden_dim * 2 if bidirectional else hidden_dim,
output_dim
)
self.dropout = nn.Dropout(dropout)
def forward(self, text):
# text shape: [batch size, sequence length]
# Get embeddings
embedded = self.embedding(text)
# embedded shape: [batch size, sequence length, embedding dim]
# Pass through LSTM
outputs, (hidden, cell) = self.lstm(embedded)
# If bidirectional, concatenate the final forward and backward hidden states
if self.lstm.bidirectional:
hidden = torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim=1)
else:
hidden = hidden[-1,:,:]
# Apply dropout
hidden = self.dropout(hidden)
# Pass through linear layer
output = self.fc(hidden)
return output
This concludes this post. My main aim to create this post was how to deal with custom dataset to use with neural networks.
The final pipeline can be viewed in this GitHub Gist