4. NLP: Seq2Seq
Sequence-to-Sequence Models
- Seq2Seq models are a neural network architecture designed to transform one sequence (of text) to another sequence.
- The input and output are both sequences and can be of varying lengths.
- These models can be used for many tasks like :
- Machine Translation
- Text Summarization
- Speech Recognition
- Image Captioning
- This post will focus on Machine Translation task.
Architecture
- It consists of a Decoder and an Encoder network.
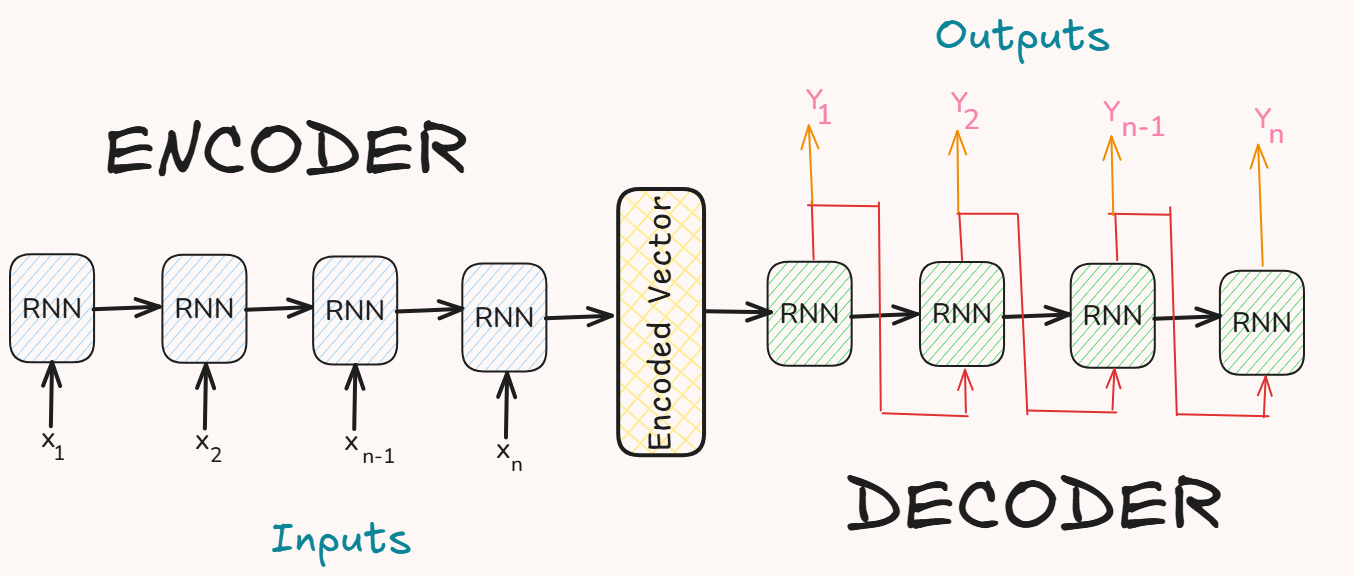
Encoder
- The encoder processes the entire input sequence and encodes it into a context vector (also called the hidden state).
- This context vector contains compressed information about the whole input sequence.
- This context vector is represented by the
- It is built using RNNs(LSTM or GRU).
class Encoder(nn.Module):
def __init__(self, input_dim, embedding_dim, hidden_dim, n_layers, dropout):
super().__init__()
self.hidden_dim = hidden_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(input_dim, embedding_dim)
self.rnn = nn.LSTM(embedding_dim, hidden_dim, n_layers, dropout=dropout)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
embedded = self.dropout(self.embedding(src))
outputs, (hidden, cell) = self.rnn(embedded) # embedded = [src length, batch size, embedding dim]
return hidden, cell
Decoder
- The decoder is also built using RNNs(LSTM or GRU) and is responsible for generating the output sequence token-by-token.
- The decoder’s initial hidden state is set to the final hidden state of the encoder.
- It starts with a special start-of-sequence token
and generates one word at a time. - The decoder uses its own previous outputs as inputs at each step (during inference).
- During training, a technique called teacher forcing is used.
class Decoder(nn.Module):
def __init__(self, output_dim, embedding_dim, hidden_dim, n_layers, dropout):
super().__init__()
self.output_dim = output_dim
self.hidden_dim = hidden_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(output_dim, embedding_dim)
self.rnn = nn.LSTM(embedding_dim, hidden_dim, n_layers, dropout=dropout)
self.fc_out = nn.Linear(hidden_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, cell):
# input shape: [batch_size]
if input.dim() == 2:
input = input.squeeze(0) # Ensure shape is [batch_size]
input = input.unsqueeze(0) # Reshape to [1, batch_size] for time-step=1
embedded = self.dropout(self.embedding(input)) # [1, batch_size, embedding_dim]
output, (hidden, cell) = self.rnn(embedded, (hidden, cell))
prediction = self.fc_out(output.squeeze(0)) # [batch_size, output_dim]
return prediction, hidden, cell
Combined Seq2Seq Model
- These 2 classes are used to build the complete Seq2Seq class.
import torch
import torch.nn as nn
import random
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, trg, teacher_forcing_ratio=0.5):
# src = [src_len, batch_size]
# trg = [trg_len, batch_size]
batch_size = trg.shape[1]
trg_len = trg.shape[0]
trg_vocab_size = self.decoder.output_dim
# Tensor to store decoder outputs
outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)
# Encode the source sequence
hidden, cell = self.encoder(src)
# First input to the decoder is the <sos> token
input = trg[0, :] # [batch_size]
for t in range(1, trg_len):
# Decode one token
output, hidden, cell = self.decoder(input, hidden, cell)
# Store the prediction
outputs[t] = output
# Decide whether to use teacher forcing
teacher_force = random.random() < teacher_forcing_ratio
# Get the highest predicted token
top1 = output.argmax(1)
# Use actual next token or predicted token as next input
input = trg[t] if teacher_force else top1
return outputs
Teacher Forcing
- Feeding the actual target token instead of the predicted one to help the model learn faster.
- Prevents the model from compounding its own early mistakes during training.
- At each time step
tuse the correct target prediction or the model’s previous prediction based on a teacher_forcing_ratio.
if random.random() < teacher_forcing_ratio:
input = trg[t] # teacher forcing
else:
input = model_pred # use model's own prediction
- Too much teacher forcing might cause model to struggle at inference time.
-
Too little teacher forcing will result in slower training.
- Thus, scheduled sampling can be used : start with a high ratio and gradually decrease it over epochs.
The complete code can be found here
Perplexity
- It is a metric to evaluate how well a language model predicts a sequence.
- It measures how surprised the model is by the actual target sequence.
Lower perplexity = less surprise = more confident predictions = better model.
-
If the model assigns probabilities $ p_1 , p_2 , p_3 , … , p_T $ to a sequence of length T, the perplexity is :
- \[\text{Perplexity} = exp(- \frac{1}{T} \sum_{t = 1} ^ T \log p_t)\]
- If loss function used is
nn.CrossEntropyLosswhich computes the negative log-likelihood, it can be exponentiated to get perplexity.
loss = nn.CrossEntropyLoss(output, target)
perplexity = torch.exp(loss) # np.exp(loss)
Beam Search
- It is a decoding strategy used to generate sequences.
-
Instead of choosing only the top-1 prediction at each step (as in greedy decoding), it keeps track of the top k most probable sequences at each step (where k is the beam width).
- At each time step:
- Expand each sequence in the beam with all possible next tokens.
- Keep only the
top-ksequences based on total log probability. - Repeat until max length or end-of-sequence (
<eos>) token is reached.
Drawbacks of Seq2Seq models
- Entire input sequence is compressed into a single fixed-size (dimension of hidden state) context vector.
- This causes the model to struggle with long / complex sequences.
-
RNNs being sequential by nature doesn’t allow parallization easily.
-
Beam search during inference adds computational overhead.
- These models don’t learn the explicit word-to-word alignment between input and output tokens.
Solution
To tackle the above drawbacks Attention and Transformer architecture are used.