7. NLP: Transformer Implementation
PyTorch Implementation
- In this post I will do detailed implementation of Attention Is All You Need Deep Dive paper.
- I have already done a deep dive of the architecture here.
This implementation is inspired from pytorch-transformer and The Annotated Transformer.
- The plan is like :
- Implement the architecture
- Prepare the Dataset and Tokenizer
- Train the model
- Perform Inference
- Visualize Attention
1. Implement the model
Imports & other setups
import torch
import torch.nn as nn
import math
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
Input Embeddings
- We will use
nn.Embeddingsto create the embeddings. - The tensor of input token’s indices in the vocabulary are passed to the embedding layer.
- The corresponding rows / vectors are extracted from the embedding matrix.
class InputEmbedding(nn.Module):
def __init__(self, d_model, vocab_size):
super().__init__()
self.d_model = d_model # size of the embedding vector of each token
self.vocab_size = vocab_size
self.embed = nn.Embedding(num_embeddings=vocab_size, embedding_dim=d_model)
def forward(self, x):
return self.embed(x) * math.sqrt(self.d_model)
-
The embedings are multiplied by $\sqrt{d_{model}}$ so as to not drown the information from positional encodings added in next step.
-
The returned embedding is of the shape
[batch_size, seq_len, d_model].
- Dropout is used to prevent overfitting. During training, dropout randomly sets a fraction of the neurons’ outputs to zero, effectively “dropping” them.
- It is used after almost all the layers in the model to improve generalization to unseen data, make training more stable and prevent overfitting due to large number of parameters.
Positional Encondings
\[PE_{(pos,2i)} = \sin\left( \frac{pos}{10000^{\frac{2i}{d_{model}}}} \right)\] \[PE_{(pos,2i+1)} = \cos\left( \frac{pos}{10000^{\frac{2i}{d_{model}}}} \right)\]-
The argument of sine/cosine = $ \text{pos} \cdot \frac{1}{10000^{2i / d_{model}}} $.
-
The term being multiplied = $ 10000^{-2i / d_{model}} $.
-
= $ \exp{(\ln{(10000^{-2i / d_{model}})})} $
-
= $ \exp{(\frac{-2i}{d_{model}} \cdot \ln{(10000)})} $
- Dealing with the argument is done in this way for numerical stability.
- This avoids the floating-point precision issues that might arise from calculating a large number raised to a very small fractional power directly.
- Also,
torch.exp(...)is vectorized, leading to more efficency.
class PositionalEncoding(nn.Module):
def __init__(self, d_model, seq_len, dropout):
super().__init__()
self.d_model = d_model
self.seq_len = seq_len
self.dropout = nn.Dropout(dropout)
pe = torch.zeros(seq_len, d_model) # matrix of shape same as embedings
pos = torch.arange(0, seq_len, dtype=torch.float).unsqueeze(1) # tensor of shape [seq_len, 1] denotes the position of token (column vector)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)) # shape of tensor div_term = [d_model // 2]
pe[:, 0::2] = torch.sin(pos * div_term) # sin to even dimensions
pe[:, 1::2] = torch.cos(pos * div_term) # cos to odd dimensions
pe = pe.unsqueeze(0) # shape of pe = [1, seq_len, d_model] (add batch dimension)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:, :x.shape[1], :].requires_grad_(False) # slicing is done to avoid shape mismatch in variable length sequence
return self.dropout(x)
-
torch.arange(0, d_model, 2)creates a tensor representing the dimension indices $2i$. self.register_buffer('pe',pe)- buffer is a part of the model’s state but it is not considered as a model parameter.
- This means that the PE will not be updated during backpropagation.
- These PE are fixed and not learned during the training as mentioned in the paper.
Layer Norm
-
The input tensor which is flowing throught the model is of shape :
[batch_size, seq_len, d_model]. - The operation iterates through every single token vector in the entire batch.
- For each of the
[batch_size, seq_len]individual vectors of sized_model, it independently calculates a mean and a variance. - It uses these specific stats to normalize that one vector.
class LayerNorm(nn.Module):
def __init__(self, d_model, epsilon = 10**-6):
super().__init__()
self.epsilon = epsilon
self.gamma = nn.Parameter(torch.ones(d_model)) # ones beacause it is multiplied
self.beta = nn.Parameter(torch.zeros(d_model)) # zeros because it is not multiplied
# x shape = [batch_size, seq_len, d_model]
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True) # along the last dimension
std = x.std(dim=-1, keepdim=True)
return self.gamma * (x - mean) / (std + self.epsilon) + self.beta
- A more mathematically correct code would be :
x_norm = (x - mean) / torch.sqrt(var + self.eps)
- But,
epsilonis not added inside thesqrtfor readability and numerical stability. Also the difference between 2 is negligible.
Position-wise fully connected feed-forward network
- It is a simple 2 layer MLP.
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout):
super().__init__()
self.layer1 = nn.Linear(d_model, d_ff)
self.layer2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.layer2(self.dropout(torch.relu(self.layer1(x))))
-
The tensor
xpasses throughlayer1to project to a larger inner dimension state (fromd_modeltod_ff). -
The output of
layer1passes through ReLU activation followed by dropout. -
Finally, the expanded tensor is brought back to orginal
d_modeldimension usinglayer2.
Multi Head Attention
class MHA(nn.Module):
def __init__(self, d_model, h, dropout):
super().__init__()
self.d_model = d_model
self.h = h # no. of heads
self.dropout = nn.Dropout(dropout)
self.d_k = d_model // h # d_k = d_v
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
self.w_o = nn.Linear(d_model, d_model)
self.attention_weights = None # for attention viualization
def forward(self, q, k, v, mask):
batch_size, seq_len, _ = q.size()
query = self.w_q(q) # shape of both query and key = [batch_size, seq_len, d_model]
key = self.w_k(k) # same shape as query
value = self.w_v(v) # same shape as query
query = query.view(batch_size, -1, self.h, self.d_k) # shape = [batch_size, seq_len, h, d_k]
query = query.transpose(1, 2) # shape = [batch_size, h, seq_len, d_k]
key = key.view(batch_size, -1, self.h, self.d_k)
key = key.transpose(1, 2)
value = value.view(batch_size, -1, self.h, self.d_k)
value = value.transpose(1, 2)
attention_scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(self.d_k) # shape = [batch_size, h, seq_len, seq_len]
if mask is not None:
attention_scores = attention_scores.masked_fill_(mask == 0, float('-inf'))
attention_weights = attention_scores.softmax(dim=-1)
self.attention_weights = attention_weights
if self.dropout is not None:
attention_weights = self.dropout(attention_weights)
attention_output = attention_weights @ value # shape = [batch_size, h, seq_len, d_k]
attention_output = attention_output.transpose(1, 2) # shape = [batch_size, seq_len, h, d_k]
attention_output = attention_output.contiguous() # makes the tensor contiguous in memory for .view as transpose may result in tensor not being stored in a contiguous block of memory
attention_output = attention_output.view(batch_size, seq_len, self.d_model) # shape = [batch_size, seq_len, d_model]
attention_output = self.w_o(attention_output) # final projection, same shape
return attention_output
- I have already discussed how attention is being computed in my previous post at this point.
if mask is not None:
attention_scores = attention_scores.masked_fill_(mask == 0, float('-inf'))
- Here mask are tensors which are used to prevent the model from paying attetnion to certain tokens.
-
It can refer to both padding mask as well as look-ahead mask.
- Padding masks :
- Padding tokens are used to group shorter sequnces to same size as all the sequences in a batch.
- These tokens are meaningless and hence must be ignored.
- Thus, padding masks are used.
- Look-Ahead masks :
- As mentioned in my previous post, these are used to prevent the decoder from looking at future tokens.
-
The value of these masks will be 1 at positions which the model has to focus on and 0 at which the positions which are to be ignored.
.masked_fill_will fill the positions which are0with- inifity.- The softmax function will deal not attend to these positions.
attention_output = self.w_o(attention_output)- Finally the output tensor is returned after passing through a final linear layer which synthesizes the information from all heads into a single useful representation.
Skip Connection / Add & Norm Block
- In the paper, layernorm was applied after residual addition (post-norm).
- x = x + Dropout(Sublayer(x))
- x = LayerNorm(x)
- But most modern implementation use pre-norm.
- x = x + Dropout(SubLayer(LayerNorm(x)))
- Pre-norm makes the gradient flow more stable during backprop.
- In post-norm, the residual is normalized after the sublayer, which can amplify or dampen gradients in unpredictable ways.
- Pre-norm normalizes before the sublayer, so the sublayer receives a well-conditioned input, making optimization easier.
class SkipConnection(nn.Module):
def __init__(self, dropout, d_model):
super().__init__()
self.dropout = nn.Dropout(dropout)
self.norm = LayerNorm(d_model)
def forward(self, x, sublayer):
return x + self.dropout(sublayer(self.norm(x))) # pre-norm
Encoder Block
Now, as all the sublayers are defined, these can be grouped together to form encoder blocks.
class EncoderBlock(nn.Module):
def __init__(self, attention, ffn, dropout, d_model):
super().__init__()
self.attention = attention
self.ffn = ffn
self.residual = nn.ModuleList([SkipConnection(dropout, d_model) for _ in range(2)])
# src_mask is used to mask out padding tokens in encoder
def forward(self, x, src_mask):
x = self.residual[0](x, lambda y: self.attention(y, y, y, src_mask))
x = self.residual[1](x, self.ffn)
return x
self.residual = nn.ModuleList([SkipConnection(dropout, d_model) for _ in range(2)])- Since in an encoder block 2 residual layers are used, they are defined in
ModuleList(list that holdsnn.Moduleobjects).
- Since in an encoder block 2 residual layers are used, they are defined in
x = self.residual[0](x, lambda y: self.attention(y, y, y, src_mask))- This line acts as a wrapper around a self attention layer along with skip connections.
- The same input
ybeing passed through asq,k,vsigninfies self attention.
- The output of self attention wrapper is passed through ffn layer then and it’s output is returned.
Encoder
- Now multiple encoder blocks are arranged one after another.
- All the encoder blocks (eg. 6 according to the paper) form the Encoder.
class Encoder(nn.Module):
def __init__(self, d_model, layers):
self.layers = layers
self.norm = LayerNorm(d_model)
def forward(self, x, mask):
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
-
Here,
layersrefer to ann.ModuleList(...)ofEncoderBlock. -
An extra normalization is also applied to the final output of the Enocder Stack, which ensures the final output is well-scaled before being passed to the decoder.
Decoder Block & Decoder
- Similar to
EncoderBlock, aDecoderBlockis designed.
class DecoderBlock(nn.Module):
def __init__(self, self_attention, cross_attention, ffn, dropout, d_model):
super().__init__()
self.self_attention = self_attention
self.cross_attention = cross_attention
self.ffn = ffn
self.residual = nn.ModuleList([SkipConnection(dropout, d_model) for _ in range(3)])
def forward(self, x, encoder_output, src_mask, trg_mask):
x = self.residual[0](x, lambda y: self.self_attention(y, y, y, trg_mask))
x = self.residual[1](x, lambda y: self.cross_attention(y, encoder_output, encoder_output, src_mask))
x = self.residual[2](x, self.ffn)
return x
x = self.residual[1](x, lambda y: self.cross_attention(y,encoder_output, encoder_output, src_mask))- This represents the cross attention part of the model, in which the key and value come from the encoder output whereas the query comes from self masked multi head attention (the code line mentioned just above this line).
- Again multiple
DecoderBlocks are stacked to form thr Decoder.
class Decoder(nn.Module):
def __init__(self, d_model, layers):
super().__init__()
self.layers = layers
self.norm = LayerNorm(d_model)
def forward(self, x, encoder_output, src_mask, trg_mask):
for layer in self.layers:
x = layer(x, encoder_output, src_mask, trg_mask)
return self.norm(x)
Final Projection / Output Layer
class Output(nn.Module):
def __init__(self, d_model, vocab_size):
super().__init__()
self.proj = nn.Linear(d_model, vocab_size)
def forward(self, x):
return self.proj(x)
- This represents the final part of the transformer architecture.
-
It converts the processed vector into a score for every word in thr vocab.
- The input vector is projected of shape
[batch_size, seq_len, d_model]is projected to shape[batch_size, seq_len, vocab_size].
Transformer Class
- Now that all the parts of the transformer are defined, it is time to wrap everything up in a single class.
class Transformer(nn.Module):
def __init__(self, encoder, decoder, src_embed, trg_embed, src_pos, trg_pos, output):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.trg_embed = trg_embed
self.src_pos = src_pos
self.trg_pos = trg_pos
self.output_layer = output
def encode(self, src, src_mask):
src = self.src_embed(src) # InputEmbedding()
src = self.src_pos(src) # PositionalEncoding()
return self.encoder(src, src_mask) # Encoder()
def decode(self, encoder_output, src_mask, trg, trg_mask):
trg = self.trg_embed(trg)
trg = self.trg_pos(trg)
return self.decoder(trg, encoder_output, src_mask, trg_mask)
def project(self, x):
return self.output_layer(x)
def forward(self, src, trg):
# Create masks for source and target
# Target mask is a combination of padding mask and subsequent mask
src_mask = (src != PAD_token).unsqueeze(1).unsqueeze(2) # (batch, 1, 1, src_len)
trg_mask = (trg != PAD_token).unsqueeze(1).unsqueeze(2) # (batch, 1, 1, trg_len)
seq_length = trg.size(1)
subsequent_mask = torch.tril(torch.ones(1, seq_length, seq_length)).to(device) # (1, trg_len, trg_len)
trg_mask = trg_mask & (subsequent_mask==1)
encoder_output = self.encode(src, src_mask)
decoder_output = self.decode(encoder_output, src_mask, trg, trg_mask)
return self.project(decoder_output)
src_mask = (src != PAD_token).unsqueeze(1).unsqueeze(2)- Here
srcis of shape[batch_size, src_len]. srcis the raw tokens before passing through the embedding layer.- The raw tokens are used instead of embeddings, because there is no nned of rich embedding vectors to know where the padding is.
- Hence,
.unsqueeze(1).unsqueeze(2)are used to convert to shape[batch_size, 1, 1, src_len].- 2
unsqueeze()calls add 2 dimensions to the mask.
- 2
PAD_tokens are defined later on.
- Here
subsequent_mask = torch.tril(torch.ones(1, seq_length, seq_length)).to(device)subsequent_maskis same as look-ahead mask.torch.ones(1, seq_length, seq_length): creates a square matrix of dimension :[1, seq_len, seq_len].torch.tril(...): Returns a lower triangular tensor by setting all the elements above diagonal 0.- Thus, a lower triangular mask of
1s is used to specify what to keep, which results in the upper triangular part to being masked out.
trg_mask = trg_mask & (subsequent_mask==1)- Here
trg_maskrepresents the padding mask andsubsequen_maskrepresents look-ahead mask. - It combines the
trg_maskand thesubsequent_maskusing a logicalAND (&)operation. - The final
trg_maskwill beTrueonly for positions that are both not a padding token and not a future token.
- Here
- After this, the encoder output is computed which is passed to the
decodemethod to get the decoder output. - The final output is passed throught the Output projection layer to get the final logits.
Building the Transformer
Now that the final Transformer class is also defined, it is time to build the transformer.
def BuildTransformer(src_vocab_size, trg_vocab_size, src_seq_len, trg_seq_len, d_model=512, N=6, h=8, dropout=0.1, d_ff=2048):
src_embed = InputEmbedding(d_model, src_vocab_size)
trg_embed = InputEmbedding(d_model, trg_vocab_size)
src_pos = PositionalEncoding(d_model, src_seq_len, dropout)
trg_pos = PositionalEncoding(d_model, trg_seq_len, dropout)
# Stack of encoders & decoders
encoder_blocks = []
for _ in range(N):
encoder_self_attention = MHA(d_model, h, dropout)
ffn = FeedForward(d_model, d_ff, dropout)
encoder_block = EncoderBlock(encoder_self_attention, ffn, dropout, d_model)
encoder_blocks.append(encoder_block)
decoder_blocks = []
for _ in range(N):
decoder_mask_attention = MHA(d_model, h, dropout)
cross_attention = MHA(d_model, h, dropout)
ffn = FeedForward(d_model, d_ff, dropout)
decoder_block = DecoderBlock(decoder_mask_attention, cross_attention, ffn, dropout, d_model)
decoder_blocks.append(decoder_block)
encoder = Encoder(d_model, nn.ModuleList(encoder_blocks))
decoder = Decoder(d_model, nn.ModuleList(decoder_blocks))
projection = Output(d_model, trg_vocab_size)
transformer = Transformer(encoder, decoder, src_embed, trg_embed, src_pos, trg_pos, projection)
for p in transformer.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return transformer
nn.init.xavier_uniform_(p)- Using Xavier or Glorot uniform initialization to initialize the weights of the layers such that the variance of the outputs is equal to the variance of the inputs.
Now the model has been created, it is time to prepare the dataset.
2. Prepare the Dataset and Tokenizer
Downloading the data
- The task is Machine Translation English-Hindi.
-
The dataset used is cfilt/iitb-english-hindi.
- I am using huggingface datasets to load it.
from datasets import load_dataset
MAX_LEN = 512
def filter_long_example(example):
return len(example['translation']['en']) < MAX_LEN and \
len(example['translation']['hi']) < MAX_LEN
ds = load_dataset("cfilt/iitb-english-hindi")
ds = ds.filter(filter_long_example)
ds = ds.filter(filter_long_example)- It filters out the sentence pairs where the English or the Hindi sentence is longer than 512 chars.
- It is done because the model expects a fixed max. seq_len.
Prepairing the Tokenizer
import tqdm
from tokenizers import Tokenizer
from tokenizers.models import BPE
from tokenizers.trainers import BpeTrainer
from tokenizers.pre_tokenizers import Whitespace
tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
# split the text based on space before tokenizing
tokenizer.pre_tokenizer = Whitespace()
def get_trainig_corpus(): # iterator for data
for i in tqdm(range(len(ds["train"]))):
yield ds["train"][i]["translation"]["en"]
yield ds["train"][i]["translation"]["hi"]
trainer = BpeTrainer(special_tokens=["[UNK]", "[PAD]", "[SOS]", "[EOS]"], vocab_size=30000)
tokenizer.train_from_iterator(get_trainig_corpus(), trainer=trainer)
tokenizer.save("hindi-english_bpe_tokenizer.json")
- The Tokenizer breaks down the raw text into smaller tokens.
- I have used a Byte-Pair-Encoding (BPE) Tpkenizer.
- BPE is an algo which starts by treating every individual character in the text as a token.
- Then it iteratively merges the most frequently occurring pair of adjacent tokens until it reaches a predetermined vocabulary size.
Prepairing the Dataset
from torch.utils.data import Dataset, DataLoader
from torch.nn.utils.rnn import pad_sequence
from tokenizers import Tokenizer
tokenizer = Tokenizer.from_file("hindi-english_bpe_tokenizer.json")
# Add special tokens
if tokenizer.token_to_id("[SOS]") is None:
tokenizer.add_special_tokens(['[SOS]'])
if tokenizer.token_to_id("[EOS]") is None:
tokenizer.add_special_tokens(['[EOS]'])
# Define special token IDs
SOS_token = tokenizer.token_to_id('[SOS]')
EOS_token = tokenizer.token_to_id('[EOS]')
PAD_token = tokenizer.token_to_id('[PAD]')
class TranslationDataset(Dataset):
def __init__(self, dataset, tokenizer, src_lang="en", tgt_lang="hi"):
self.dataset = dataset
self.tokenizer = tokenizer
self.src_lang = src_lang
self.tgt_lang = tgt_lang
def __len__(self):
return len(self.dataset)
def __getitem__(self, idx):
src_text = self.dataset[idx]["translation"][self.src_lang]
tgt_text = self.dataset[idx]["translation"][self.tgt_lang]
# Tokenize and add special tokens
src_ids = [SOS_token] + self.tokenizer.encode(src_text).ids + [EOS_token]
tgt_ids = [SOS_token] + self.tokenizer.encode(tgt_text).ids + [EOS_token]
return torch.tensor(src_ids), torch.tensor(tgt_ids)
train_dataset = TranslationDataset(ds["train"], tokenizer)
val_dataset = TranslationDataset(ds["validation"], tokenizer)
def collate_fn(batch):
src_batch, tgt_batch = [], []
for src_sample, tgt_sample in batch:
src_batch.append(src_sample)
tgt_batch.append(tgt_sample)
# Pad sequences to the length of the longest sequence in the batch
src_batch = pad_sequence(src_batch, padding_value=PAD_token, batch_first=True)
tgt_batch = pad_sequence(tgt_batch, padding_value=PAD_token, batch_first=True)
return src_batch, tgt_batch
# Create the DataLoaders
batch_size = 32
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, collate_fn=collate_fn)
val_dataloader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, collate_fn=collate_fn)
__getitem__(self, idx)- Retrieves the corresponding source and target sentences for the given idx
- The source and target text (strings) are encoded and converted into a list of token IDs.
- Add the
<SOS>(start of sequence) &<EOS>(end of sentence) tokens at start and end of the sequence respectively. - This list of IDs are converted to a tensor.
collate_fn(batch)- It pads all the sentence in a batch to the same length.
pad_sequence(...)pads all the tensors to the length of the longest tensor in the list.
DataLoader(...)- It takes the Dataset and provides an iterable over it.
shuffle=True: shuffles the data at every epoch to prevent the model from learning the order of the training examples.
3. Train the model
Now, the dataset is processed and tokenized it is time to train the model.
Parameters of the model & Making the model
config = {
"epochs": 15,
"batch_size": 16,
"d_model": 512,
"num_layers": 6,
"num_heads": 8,
"d_ff": 2048,
"dropout": 0.1,
"learning_rate": 0.0001,
"max_seq_len": 512,
"accumulation_steps": 4,
"logging_interval": 50
}
src_vocab_size = tokenizer.get_vocab_size()
trg_vocab_size = tokenizer.get_vocab_size()
src_seq_len = 512
trg_seq_len = 512
d_model = 256
num_heads = 8
num_layers = 6
d_ff = 2048
dropout = 0.1
PAD_token = tokenizer.token_to_id('[PAD]')
- Create the model :
model = BuildTransformer(src_vocab_size,
trg_vocab_size,
src_seq_len,
trg_seq_len,
d_model,
num_layers,
num_heads,
dropout,
d_ff).to(device)
Loss Function & Optimizer
criterion = nn.CrossEntropyLoss(ignore_index=PAD_token)
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9)
- The loss used is
CrossEntropyLoss. It is perfect for multi-class classification tasks like thisignore_index=PAD_token- Tells the loss function to completely ignore the model’s predictions for any position where the true word is a padding token.
- This ensures that the model isn’t penalized for what it predicts after a sentence has ended.
Training Loops & Optimizations
scaler = GradScaler()
def train_epoch(model, dataloader, optimizer, criterion, device, config, epoch_num):
model.train()
epoch_start_time = time.time()
total_epoch_loss = 0.0
chunk_start_time = time.time()
chunk_losses = []
chunk_tokens = 0
num_batches = len(dataloader)
optimizer.zero_grad()
for i, (src_batch, tgt_batch) in enumerate(dataloader):
src_batch = src_batch.to(device)
tgt_batch = tgt_batch.to(device)
tgt_input = tgt_batch[:, :-1]
tgt_out = tgt_batch[:, 1:]
with torch.cuda.amp.autocast():
output = model(src_batch, tgt_input)
output_flat = output.contiguous().view(-1, output.shape[-1])
tgt_out_flat = tgt_out.contiguous().view(-1)
loss = criterion(output_flat, tgt_out_flat)
loss = loss / config['accumulation_steps']
scaler.scale(loss).backward()
if (i + 1) % config['accumulation_steps'] == 0:
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()
current_loss = loss.item() * config['accumulation_steps']
# To simulate the loss for a single batch
chunk_losses.append(current_loss)
total_epoch_loss += current_loss
num_target_tokens = (tgt_batch != PAD_token).sum().item()
chunk_tokens += num_target_tokens
if (i + 1) % config['logging_interval'] == 0:
avg_chunk_loss = sum(chunk_losses) / len(chunk_losses)
chunk_ppl = math.exp(avg_chunk_loss)
time_for_chunk = time.time() - chunk_start_time
bps = chunk_tokens / time_for_chunk
print(f" Batch {i+1:5d}/{num_batches:5d} | Avg Loss (last {config['logging_interval']}): {avg_chunk_loss:.4f} | "
f"PPL: {chunk_ppl:7.2f} | Tokens/Sec: {bps:7.2f}")
chunk_start_time = time.time()
chunk_losses = []
chunk_tokens = 0
epoch_duration = time.time() - epoch_start_time
avg_epoch_loss = total_epoch_loss / num_batches
return avg_epoch_loss, epoch_duration
- To speed up the training and improve stability, 3 optimization techniques are used.
1. Mixed Precision Training
- Perform calculations in lower precision formats
float16instead offloat32. with torch.cuda.amp.autocast():- automatically casts operations inside its block to the optimal precision.
scaler.scale(loss).backward()- Since
float16has a smaller numerical range, gradients may become so small, almost 0. - To prevent this underflow,
GradScalerscales the loss before backpropagation.
- Since
scaler.unscale_(optimizer)- Unscales the gradients that were scaled before back to their correct values.
scaler.step(optimizer)- If no
inf/NaNgradients are found, invokes optimizer.step() using the unscaled gradients. - Otherwise,
optimizer.step()is skipped to avoid corrupting the params. - (Perform a single optimization step to update parameter).
- If no
2. Gradient Accumulation
- It is a trick to simulate a very large batch size.
- Instead of updating the model’s weights after every batch, the gradients are calculated and accumulated over several batches.
-
Then the weights are updated. Thus, simulates training on a large batch.
- ` if (i + 1) % config[‘accumulation_steps’] == 0:`
- This block activates after the
accumulation_stepsnumber of batches. - Under this block, the weigths are updated.
- Also, the gradients are cleared after the accumulated gradients have been used to update the model weights.
- This block activates after the
loss = loss / config['accumulation_steps']- This is done to average the gradients.
- Dividing the loss for each small batch ensures that the final accumulated gradient is the correct average.
3. Gradient Clipping
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)- It checks the overall magnitude (or norm) of all the gradients combined.
- If this norm exceeds a set threshold (1.0), the gradients are scaled down to be within that threshold.
All the chunk lines are used to log the progress during training.
output_flat = output.contiguous().view(-1, output.shape[-1])
tgt_out_flat = tgt_out.contiguous().view(-1)
loss = criterion(output_flat, tgt_out_flat)
- The
nn.CrossEntropyLossexpects the prediction tensor to be2Dand the target tensor to be1D. -
Thus, the prediction’s
batch&seq_lendimension are merged. tgt_input = tgt_batch[:, :-1]- creates the model’s input by taking the target sequence and removing the final
[EOS]token.
- creates the model’s input by taking the target sequence and removing the final
tgt_out = tgt_batch[:, 1:]- creates the ground truth labels by removing the initial
[SOS]token,
- creates the ground truth labels by removing the initial
- Thus, creating a one-step-shifted pair.
- This is done for teacher forcing setup.
Validation Loop
def evaluate(model, dataloader, criterion, device):
model.eval()
total_loss = 0
with torch.no_grad():
data_iterator = tqdm(dataloader, desc="Validating")
for src_batch, tgt_batch in data_iterator:
src_batch = src_batch.to(device)
tgt_batch = tgt_batch.to(device)
tgt_input = tgt_batch[:, :-1]
tgt_out = tgt_batch[:, 1:]
output = model(src_batch, tgt_input)
output_flat = output.contiguous().view(-1, output.shape[-1])
tgt_out_flat = tgt_out.contiguous().view(-1)
loss = criterion(output_flat, tgt_out_flat)
total_loss += loss.item()
return total_loss / len(dataloader)
- Similar to
train_epochcode with the mahow difference being that the model is inmodel.eval()mode. - Thus, gradients are not calculated and only forward pass is performed.
Final Main Loop
for epoch in range(config['epochs']):
print(f"--- Epoch {epoch+1:02d}/{config['epochs']:02d} ---")
train_loss, train_duration = train_epoch(
model, train_dataloader, optimizer, criterion, device, config, epoch + 1
)
val_loss = evaluate(
model, val_dataloader, criterion, device
)
train_ppl = math.exp(train_loss)
val_ppl = math.exp(val_loss)
mins, secs = divmod(train_duration, 60)
print(f"End of Epoch: {epoch+1:02d} | Time: {int(mins)}m {int(secs)}s")
print(f"\tEpoch Train Loss: {train_loss:.3f} | Epoch Train PPL: {train_ppl:7.3f}")
print(f"\tEpoch Val. Loss: {val_loss:.3f} | Epoch Val. PPL: {val_ppl:7.3f}")
print("-" * 70)
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'scaler_state_dict': scaler.state_dict(),
'loss': val_loss,
}, CHECKPOINT_PATH)
-
Both the
train_epoch&evaluatefunctions are called. -
The model’s state will be saved after evry epoch (1 pass over the entire train dataset).
4. Inference
- There are 2 ways of doing inference.
Greedy Inference
def translate_sentence(sentence: str, model, tokenizer, device, max_len=100):
model.eval()
src_ids = [tokenizer.token_to_id('[SOS]')] + tokenizer.encode(sentence).ids + [tokenizer.token_to_id('[EOS]')]
src_tensor = torch.tensor(src_ids).unsqueeze(0).to(device)
src_mask = (src_tensor != PAD_token).unsqueeze(1).unsqueeze(2)
with torch.no_grad():
encoder_output = model.encode(src_tensor, src_mask)
tgt_tokens = [tokenizer.token_to_id('[SOS]')]
for _ in range(max_len):
tgt_tensor = torch.tensor(tgt_tokens).unsqueeze(0).to(device)
trg_mask_padding = (tgt_tensor != PAD_token).unsqueeze(1).unsqueeze(2)
subsequent_mask = torch.tril(torch.ones(1, tgt_tensor.size(1), tgt_tensor.size(1))).to(device)
trg_mask = trg_mask_padding & (subsequent_mask == 1)
with torch.no_grad():
decoder_output = model.decode(encoder_output, src_mask, tgt_tensor, trg_mask)
logits = model.project(decoder_output)
pred_token = logits.argmax(dim=-1)[0, -1].item()
tgt_tokens.append(pred_token)
if pred_token == tokenizer.token_to_id('[EOS]'):
break
translated_text = tokenizer.decode(tgt_tokens, skip_special_tokens=True)
return translated_text
Beam Search
def translate_beam_search(sentence, model, tokenizer, device, pad_token_id, beam_size=3, max_len=50):
model.eval()
src_ids = [tokenizer.token_to_id('[SOS]')] + tokenizer.encode(sentence).ids + [tokenizer.token_to_id('[EOS]')]
src_tensor = torch.tensor(src_ids).unsqueeze(0).to(device)
src_mask = (src_tensor != pad_token_id).unsqueeze(1).unsqueeze(2)
with torch.no_grad():
encoder_output = model.encode(src_tensor, src_mask)
initial_beam = (torch.tensor([tokenizer.token_to_id('[SOS]')], device=device), 0.0)
beams = [initial_beam]
for _ in range(max_len):
new_beams = []
for seq, score in beams:
if seq[-1].item() == tokenizer.token_to_id('[EOS]'):
new_beams.append((seq, score))
continue
tgt_tensor = seq.unsqueeze(0)
trg_mask_padding = (tgt_tensor != pad_token_id).unsqueeze(1).unsqueeze(2)
subsequent_mask = torch.tril(torch.ones(1, tgt_tensor.size(1), tgt_tensor.size(1))).to(device)
trg_mask = trg_mask_padding & (subsequent_mask == 1)
with torch.no_grad():
decoder_output = model.decode(encoder_output, src_mask, tgt_tensor, trg_mask)
logits = model.project(decoder_output)
last_token_logits = logits[0, -1, :]
log_probs = F.log_softmax(last_token_logits, dim=-1)
top_log_probs, top_next_tokens = torch.topk(log_probs, beam_size)
for i in range(beam_size):
next_token = top_next_tokens[i]
log_prob = top_log_probs[i].item()
new_seq = torch.cat([seq, next_token.unsqueeze(0)])
new_score = score + log_prob
new_beams.append((new_seq, new_score))
new_beams.sort(key=lambda x: x[1], reverse=True)
beams = new_beams[:beam_size]
if beams[0][0][-1].item() == tokenizer.token_to_id('[EOS]'):
break
best_seq = beams[0][0]
return tokenizer.decode(best_seq.tolist(), skip_special_tokens=True)
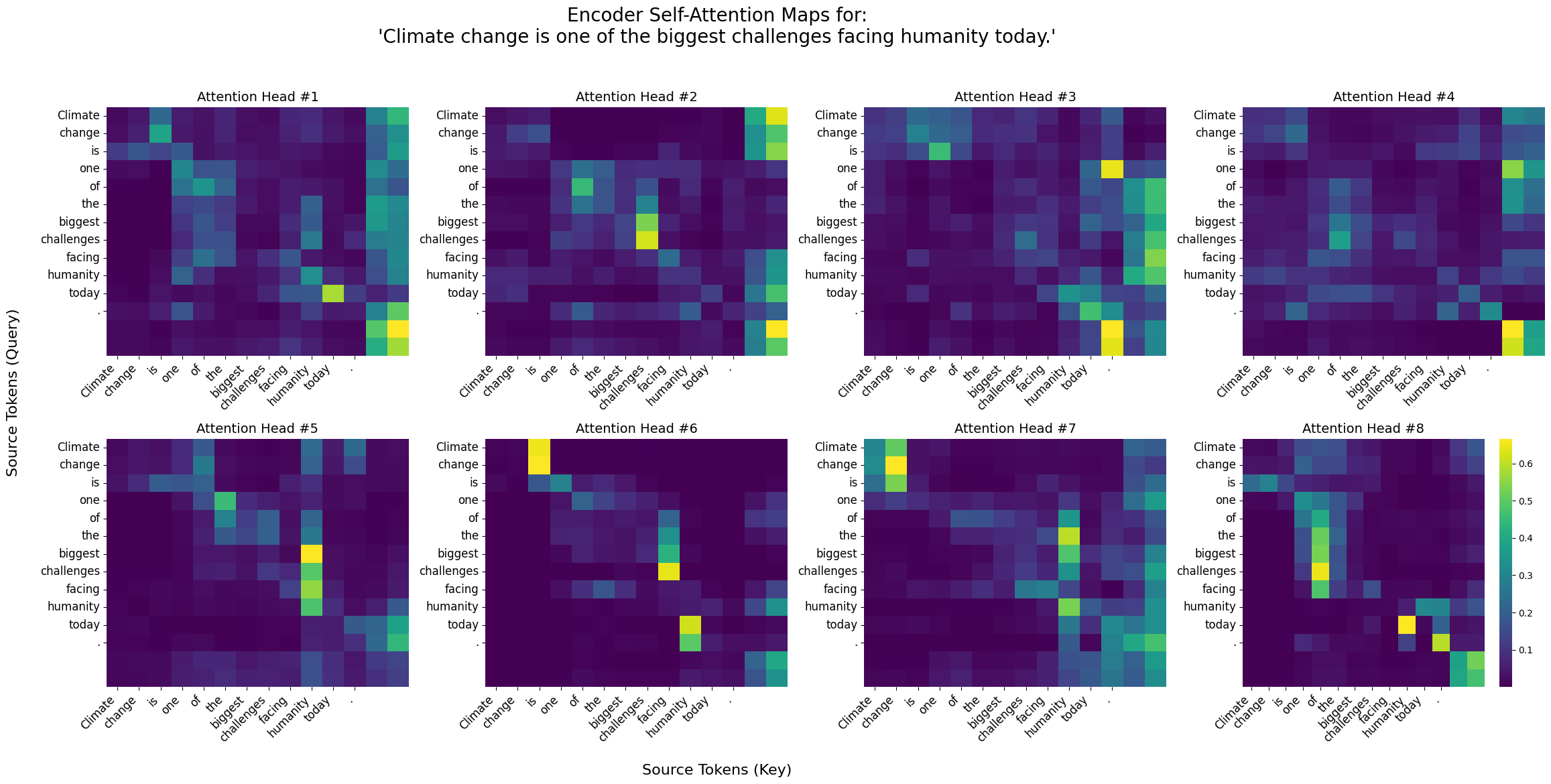
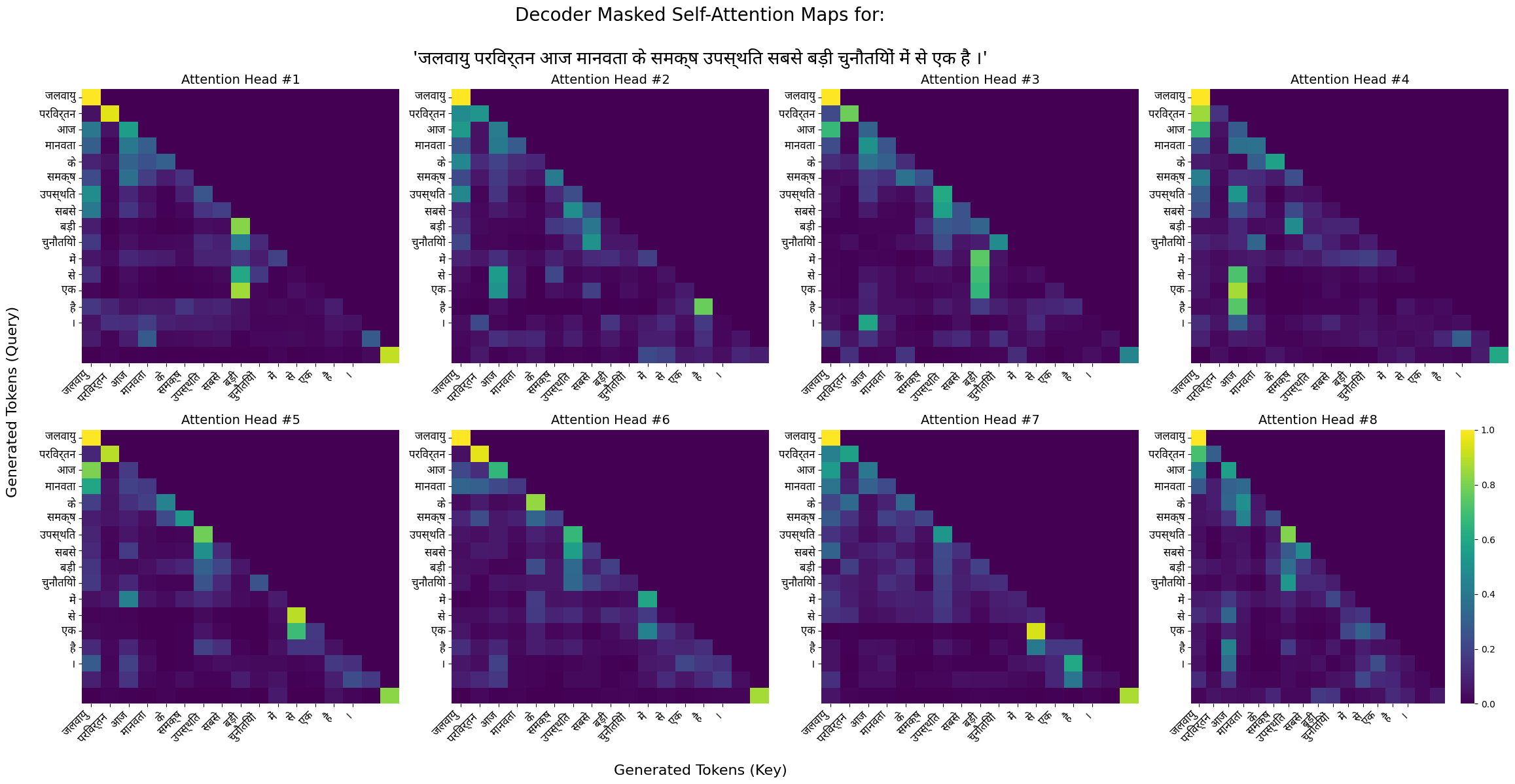
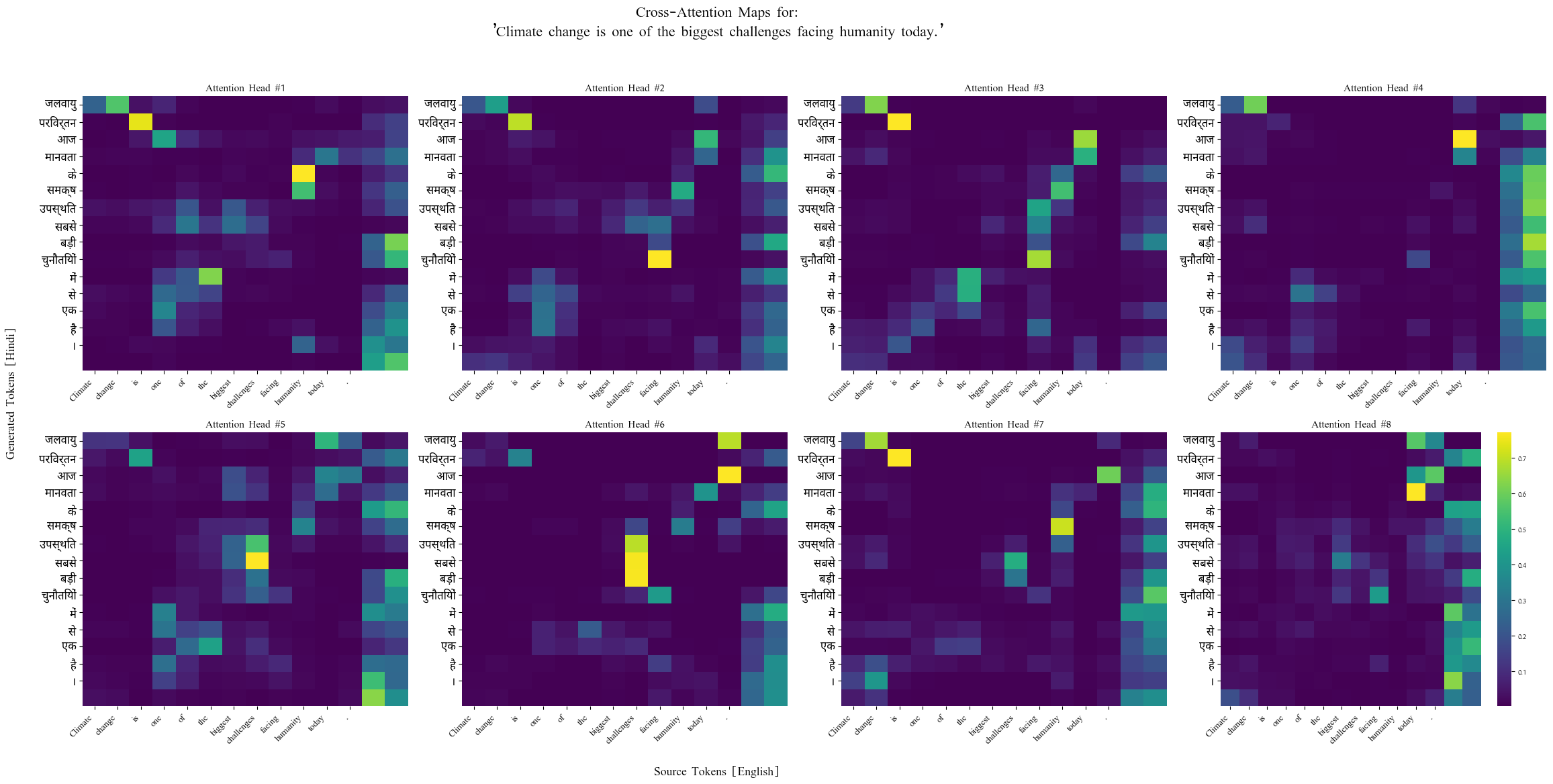
5. Visualize Attention
- Source : Climate change is one of the biggest challenges facing humanity today.
- Generated Translation: जलवायु परिवर्तन आज मानवता के समक्ष उपस्थित सबसे बड़ी चुनौतियों में से एक है ।
Encoder Self Attention Heat Map
Decoder Self Masked Attention Heat Map
Encoder-Decoder Cross Attention Heat Map
- The model was trained over 6 Colab Sessions.
-
Each session’s notebook cab be found here.
- All the code along with instructions to perform inference can be found here.
Total number of parameters of the model = 40,433,968.
With this, the complete implementation & training of the transformer model is completed.